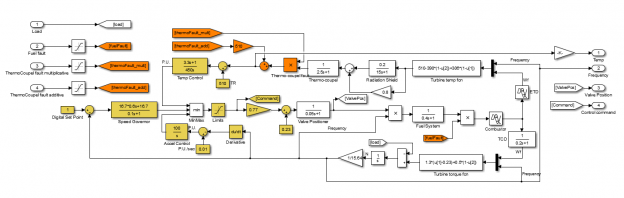
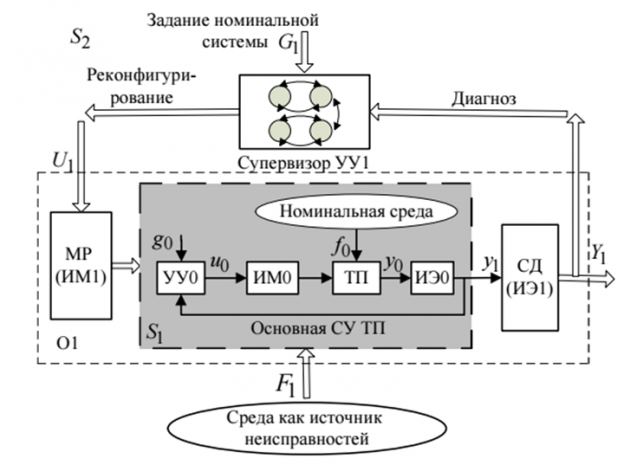
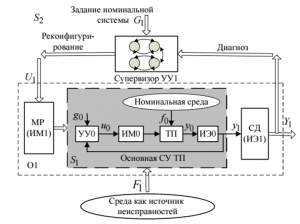
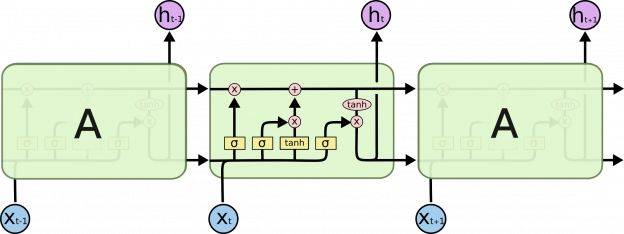
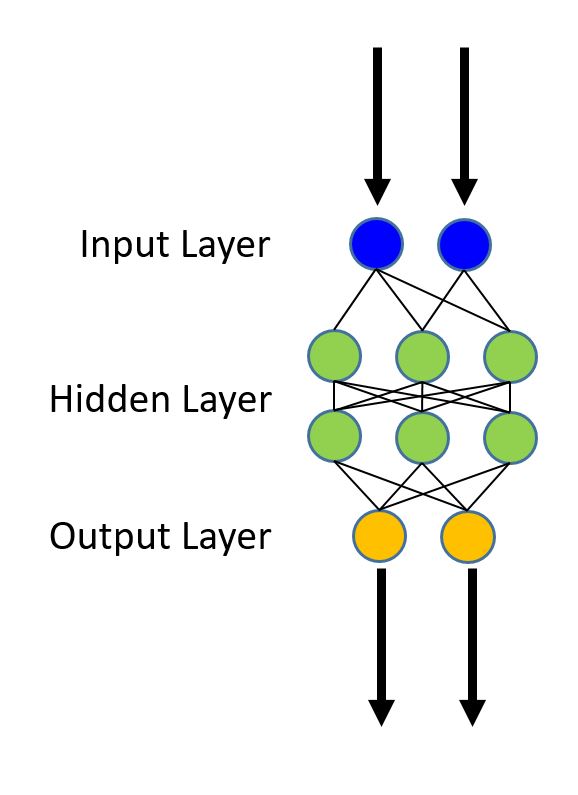
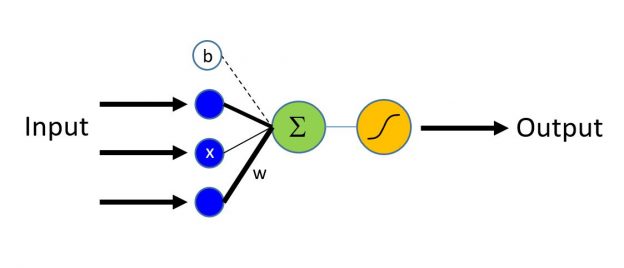
В качестве простейшей иллюстрации рассмотрим классификацию датасета MNIST двумя подходами, и. заодно, познакомимся с двумя инструментами.
Датасет MNIST представляет собой набор из 70000 изображений рукописных цифр от 0 до 9, который делится на 60000 обучающих изображений и 10000 тестовых. Подробное его описание и он сам доступены по адресу https://www.openml.org/d/554.
Цифры были нормализованы по размеру и центрированы на изображении фиксированного размера. Исходные черно-белые изображения из NIST были нормализованы по размеру, чтобы поместиться в поле размером 20×20 пикселей при сохранении их соотношения сторон. После нормализации изображения сглажены, вследствие чего содержат уровни серого. Полученные изображения центрированы в поле 28×28 путем вычисления центра масс пикселей и перемещения изображения таким образом, чтобы расположить эту точку в центре.
Когда-то этот датасет был одним из соревновательных датасетов для научных исследований в области классификации изображений, однако, на данный момент современными средствами и методами точность классификации приблизилась к 100%, а датасет получил роль учебного и является хорошей базой для первых шагов в машинном обучении.
Одним из наиболее известных фреймворков для машинного обучения с использованием классических методов является scikit-learn.
Читать далее →