
Рекуррентные нейронные сети
Человек не начинает каждый момент свое мышление с нуля. В то время, как вы читаете эту статью, вы воспринимаете каждое слово, основываясь на понимании значения предыдущих слов. Вы не забываете все и не начинаете анализировать каждое слово в отдельности. В целом, все ваши мысли имеют последствия (откладываются в памяти).
Традиционные нейронные сети не могут запоминать информацию, и это, вероятно, является их главным недостатком. Например, представьте, что вы хотите классифицировать события происходящее в каждом кадре фильма. Непонятно, как классическая нейронная сеть может использовать предыдущие свои выводы для дальнейших решений.
Рекуррентные сети направлены на исправление этого недостатка: они содержат циклы, которые позволяют сохранять информацию.

Рекуррентные сети имеют петли
На рисунке выше, элемент нейронной сети A получает на вход некоторый вход x и возвращает значение h. Цикл позволяет информации передаваться к следующим шагам.
Из-за циклов рекуррентные нейронные сети становятся трудными в понимании. Однако, все не так сложно: они имеют много общего с обыкновенными сетями. Рекуррентную сеть можно развернуть в последовательность одинаковых обыкновенных нейронных сетей, передающих информацию к последующим, например, как изображено на рисунке ниже.
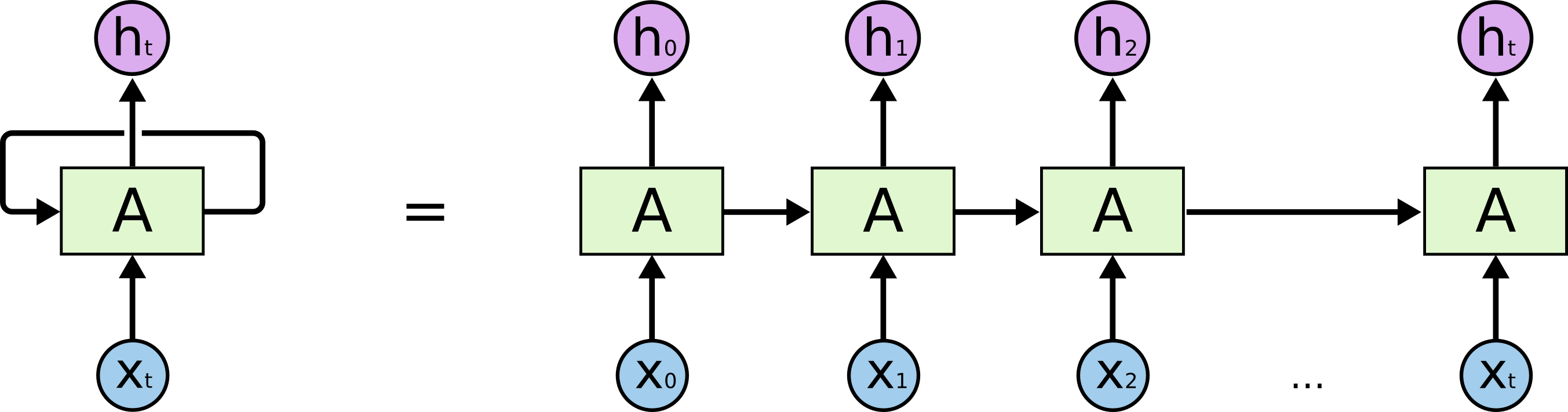
Развернутая рекуррентная сеть
Эта цепочка показывает, что природа рекуррентных нейронных сетей тесно связана с последовательностями и списками. Они являются естественными архитектурами для использования таких данных.
И, естественно, они используются. За последние несколько лет был достигнут значительный успех в применении рекуррентных нейронных сетей для распознавания речи, моделирования языка, перевода, распознавания изображений и других интересных вещей. Оставим размышления о способах применения рекуррентных сетей для Андрея Карпатого в его блоге: The Unreasonable Effectiveness of Recurrent Neural Networks.
Существенное влияние на успех оказало появление LSTM сетей — очень специфического типа рекуррентных нейронных сетей, которые работают для большого количества задач значительно лучше, чем обыкновенные сети. Практически все выдающиеся результаты, достигнутые с помощью рекуррентных нейронных сетей основаны на них. В статье будут рассмотрены именно LSTM сети.
Проблема долгосрочных зависимостей
Одной из основных идей рекуррентных сетей является возможность использовать в текущей задаче информацию полученную ранее. Например использовать предыдущие кадры видео для анализа текущего кадра. Однако, умеют ли это делать рекуррентные сети? — И да, и нет.
Иногда необходимо лишь взглянуть на предыдущие данные для решения текущей задачи. Например, лингвистическая модель пытается предсказать последующие слова, основываясь на предыдущих словах. Если вы хотите предсказать последнее слово во фразе «Облака в небе«, вам не нужен какой-либо другой контекст, так как довольно очевидно, что следующее слово будет «небо«. В таких задачах, когда разрыв между необходимыми данными и текущей задачей достаточно невелик, рекуррентные нейронные сети, как правило, могут справиться с задачей.
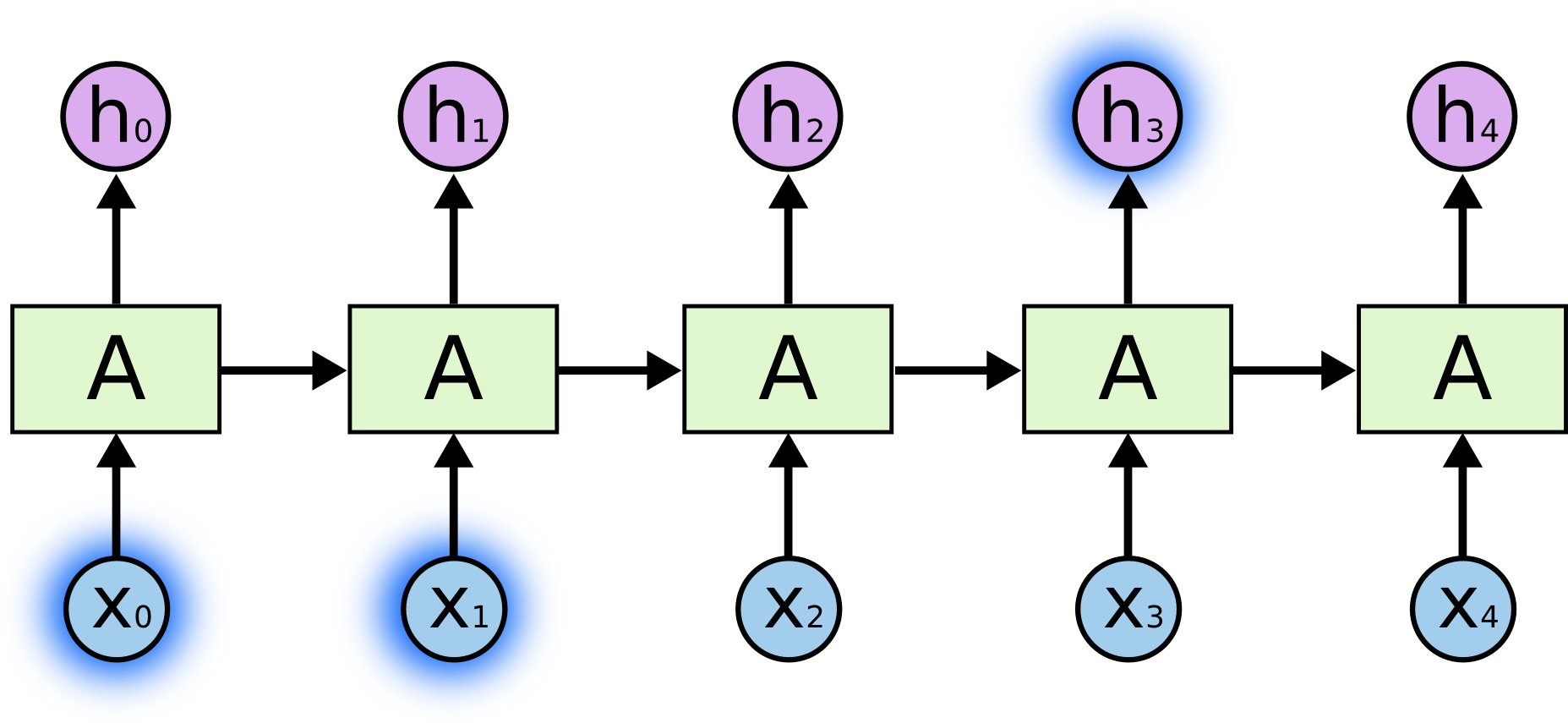
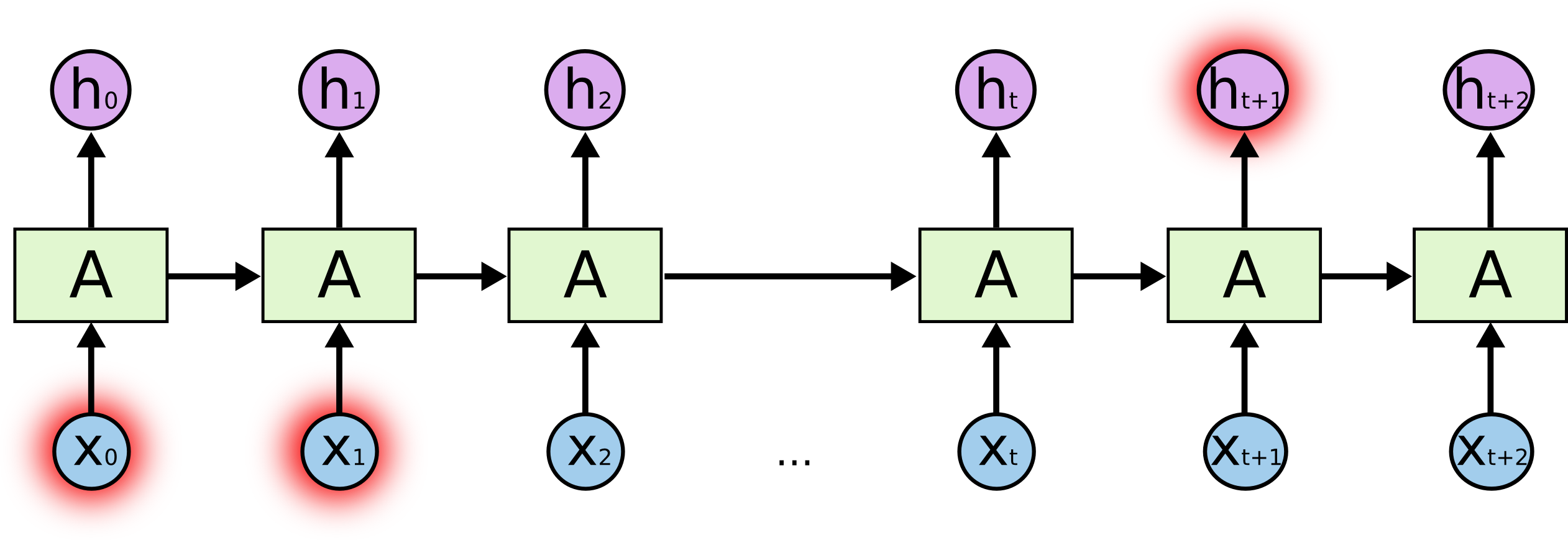
Однако, иногда для решения задачи необходимо больше контекста. Например, для предсказания последнего слова во фразе «Я вырос во Франции. … Я свободно говорю по-Французски» непосредственно стоящие перед искомым словом слова говорят лишь о том, что следующее слово, наверняка, будет языком, но для его определения необходим более ранний контекст. Вполне вероятно, что разрыв между необходимым контекстом и искомым словом будет весьма велик.
К сожалению, когда этот разрыв растет рекуррентная нейронная сеть теряет способность использовать эту информацию.
Теоретически рекуррентные нейронные сети в состоянии обрабатывать такие долгосрочные зависимости (а человек может тщательно выбирать параметры для сети). Однако, на практике рекуррентные нейронные сети не в состоянии обучиться в таких задачах. Проблема была изучена специалистами Хохрайтером (1991) [Германия] и Бенджио и др.(1994), которые определили фундаментальные причины сложности этой задачи.
Однако, LSTM сети не имеют такой проблемы.
LSTM сети
Долгая краткосрочная память (Long short-term memory), обычно называемая LSTM-сетями — это особый вид рекуррентных нейронных сетей, способных к запоминанию долговременных зависимостей. Они были введены Сеппом Хохрайтером и Юргеном Шмидхубером в 1997 году и были использованы и развиты многими исследователями в своих работах. Эти сети работают в широком спектре задач и довольно часто используются.
LSTM сети были разработаны для решения проблемы долговременных зависимостей. Запоминание информации на продолжительный срок — это одна из основных особенностей этих сетей, не требующая продолжительного обучения.
Все рекуррентные сети можно представить в форме цепочки повторяющихся обыкновенных нейронных сетей. Обычную рекуррентную нейронную сеть можно представить в очень простой форме, как слой с tanh функцией активации.
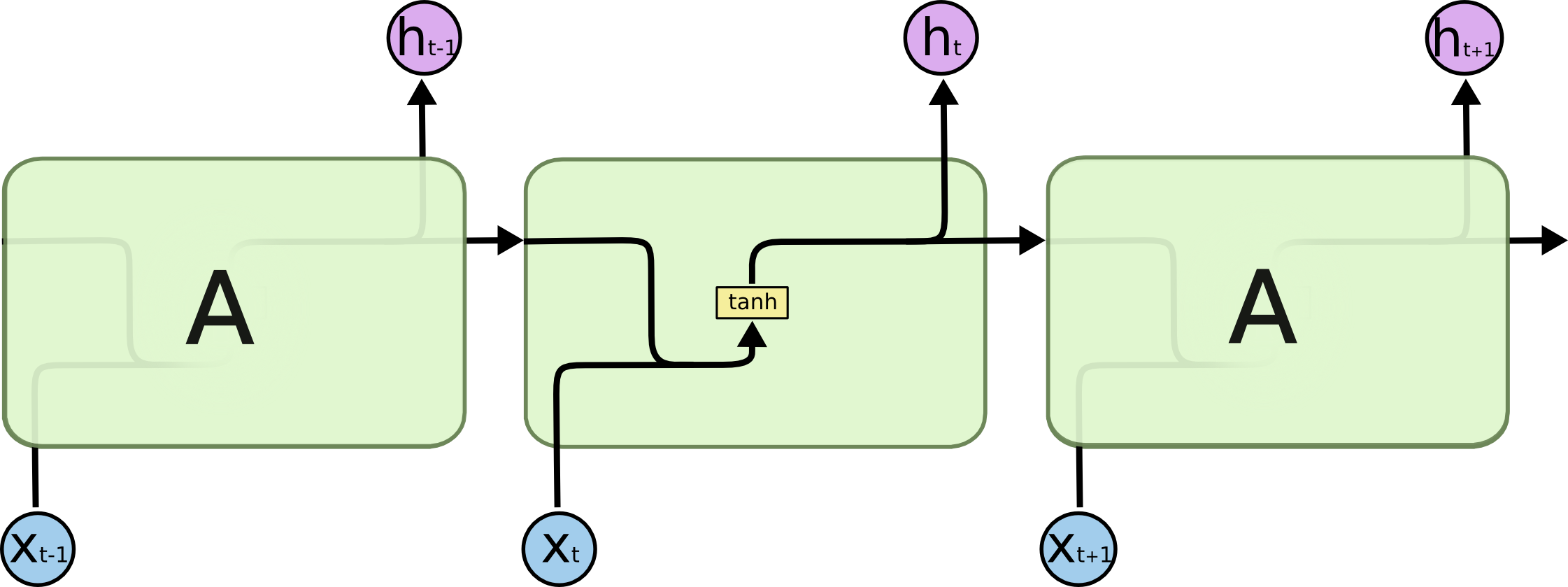
Повторяющиеся модули в стандартных рекуррентных сетях, содержащие один слой
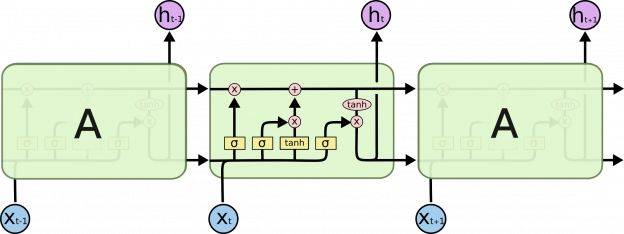
LSTM-сети также можно представить в такой форме, однако повторяющиеся модули имеют значительно более сложную структуру: вместо однослойной нейронной сети они имеют четырехслойную, организованную очень специфическим образом.
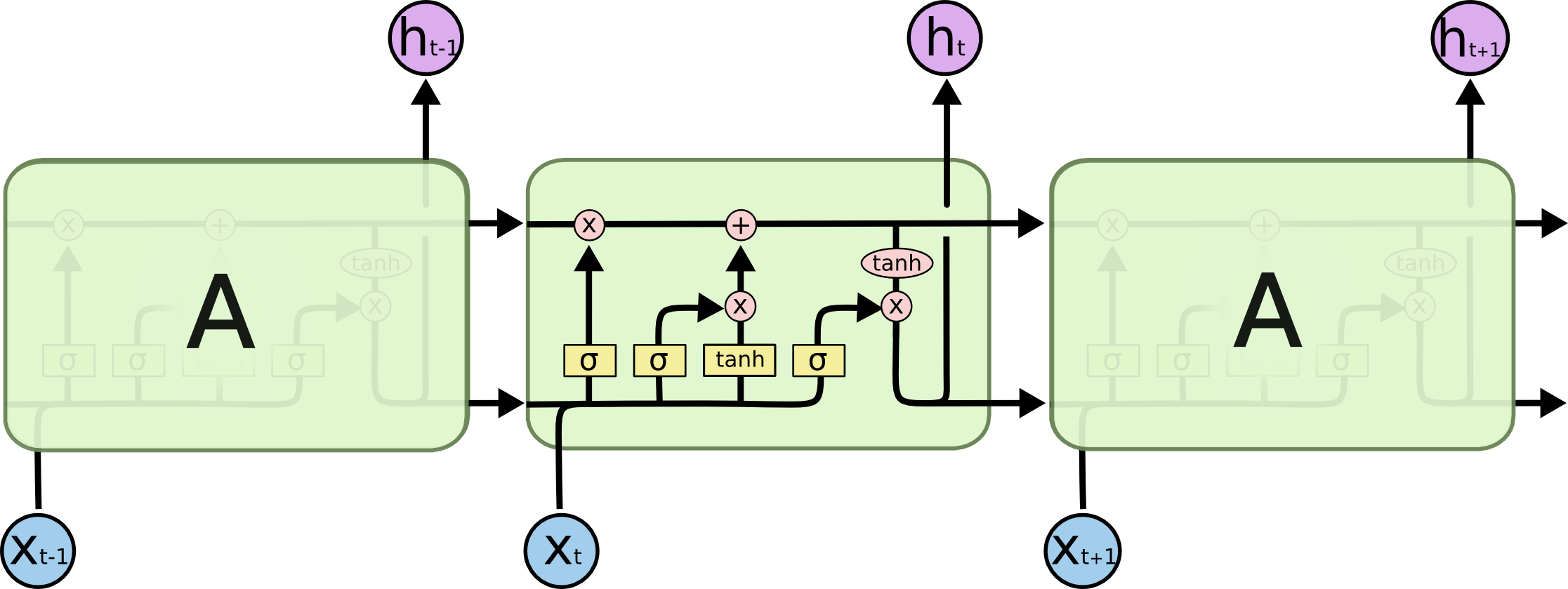
Повторяющиеся модули в LSTM-сети, содержащие 4 слоя
Однако не беспокойтесь об этих тонкостях: мы рассмотрим пошагово происходящее в этой сети чуть позже, а сейчас договоримся об используемых условных обозначениях.

В приведенной выше диаграмме, каждая линия обозначает вектор передающий данные с выхода одного узла на вход другого. Розовый круг обозначает поэлементные операции, такие как сложение векторов. Желтые прямоугольники обозначают обучаемые нейросетевые слои. Соединяющимися линиями обозначена конкатенация, а разделяющимися — копирование.
Базовая идея LSTM-сетей
Ключ к пониманию LSTM-сети — это состояние ячейки, горизонтальная линия, проходящая через верхнюю часть диаграммы.
Состояние ячейки напоминает конвейерную ленту: оно проходит сквозь всю цепочку лишь с некоторыми незначительными линейными взаимодействиями. Для информации это означает, что она может проходить практически без изменений.

Способность сети добавлять или удалять информацию в ячейке, тщательно регулируется структурами, называющимися вентилями.
Вентили — это способ ограничения прохождения информации. Они состоят из нейронного слоя с сигмовидной функцией активации и выполняют операцию поэлементного умножения.
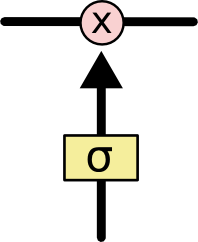
Выход сигмоиды — это число от 0 до 1, обозначающее какая часть каждого элемента вектора будет пропущена далее. Значение 0 можно понимать, как «ничего не пропускать», в то время как значение 1 — «пропустить полностью»
LSTM имеют три таких элемента для защиты и контроля состояния ячейки.
Пошаговый анализ работы LSTM-сети
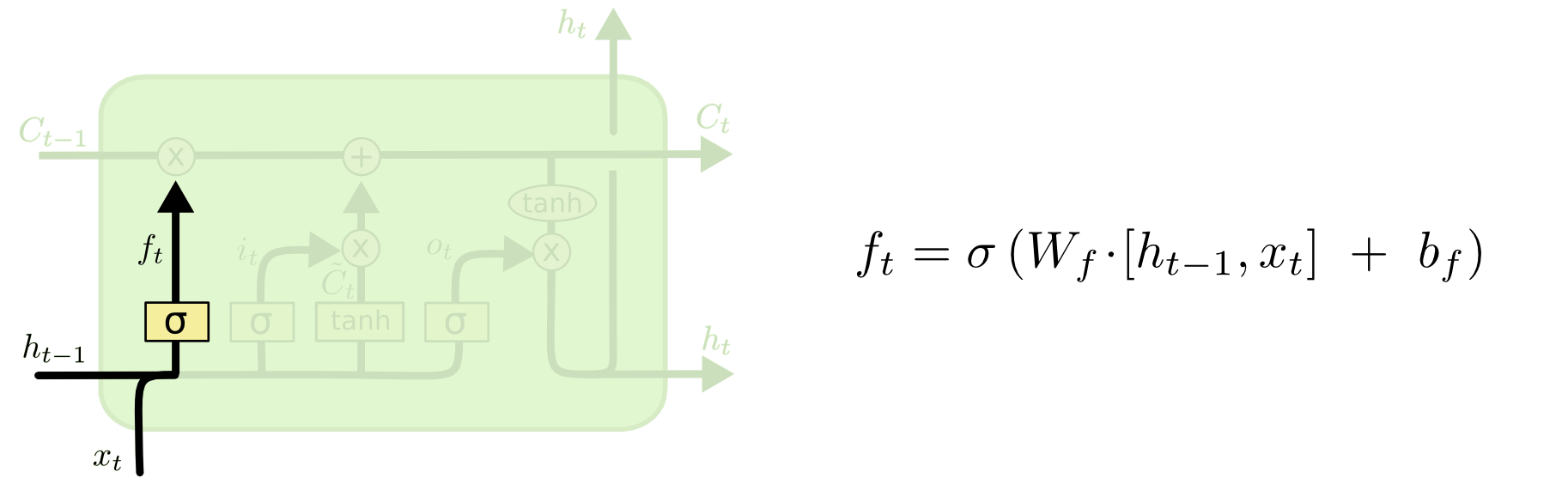
Первый шаг в LSTM сети — это решение, какую информацию необходимо выбросить из состояния ячейки. Решение формируется сигмовидным слоем называемым входным вентилем. Он обозначен, как \(h_{t-1}\) и \(x_{t}\) и имеют числовой выход со значением между 0 и 1 для каждой ячейки состояния \(C_{t-1}\). 1 обозначает «полностью сохранить», 0 — «полностью избавиться».
Вернемся к примеру лингвистической модели предсказания слова, основываясь на предыдущих словах. В подобной задаче ячейки могут содержать пол рассматриваемого объекта для использования верного местоимения. Однако, когда мы видим новую тему, можно забыть пол старого объекта.
Следующим шагом необходимо определить, какая информация будет храниться в состоянии ячейки. Этот этап состоит из двух частей. Первая: входной вентиль должен определить какие значения будут обновляться, а tanh слой создает вектор новых кандидатов на значения \(\tilde C_t\), которые могут быть добавлены в состояние. На следующем шаге мы комбинируем два созданных вектора для обновления состояния.
В примере с языковой моделью, мы хотим добавить пол нового объекта в состояние ячейки для замены устаревшего.
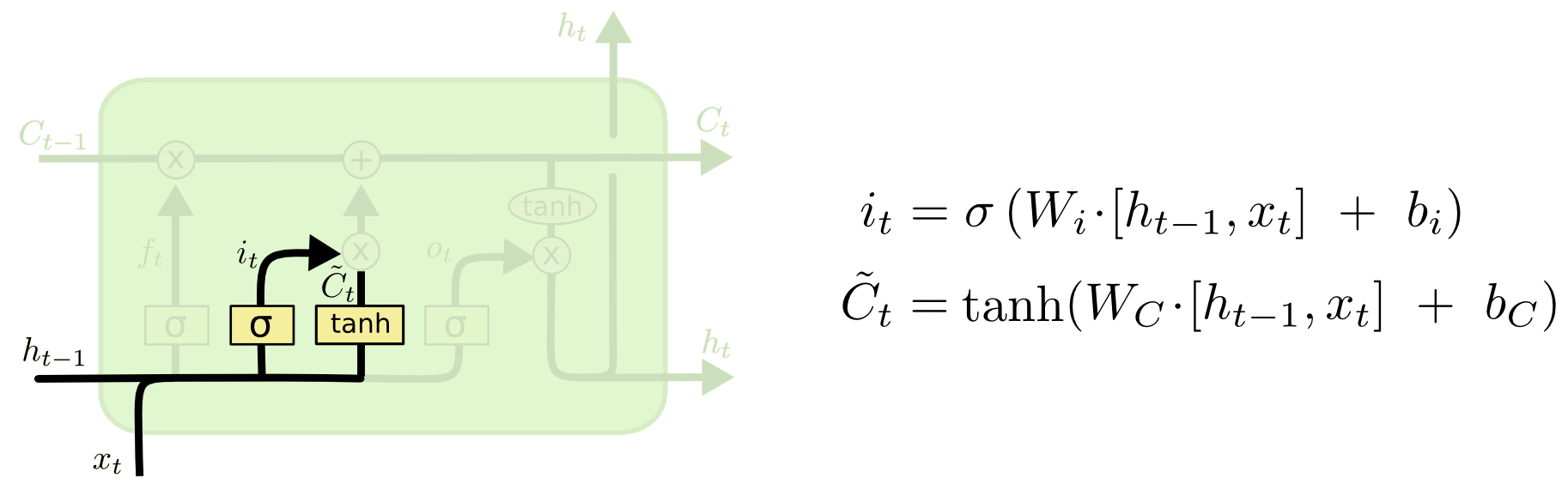
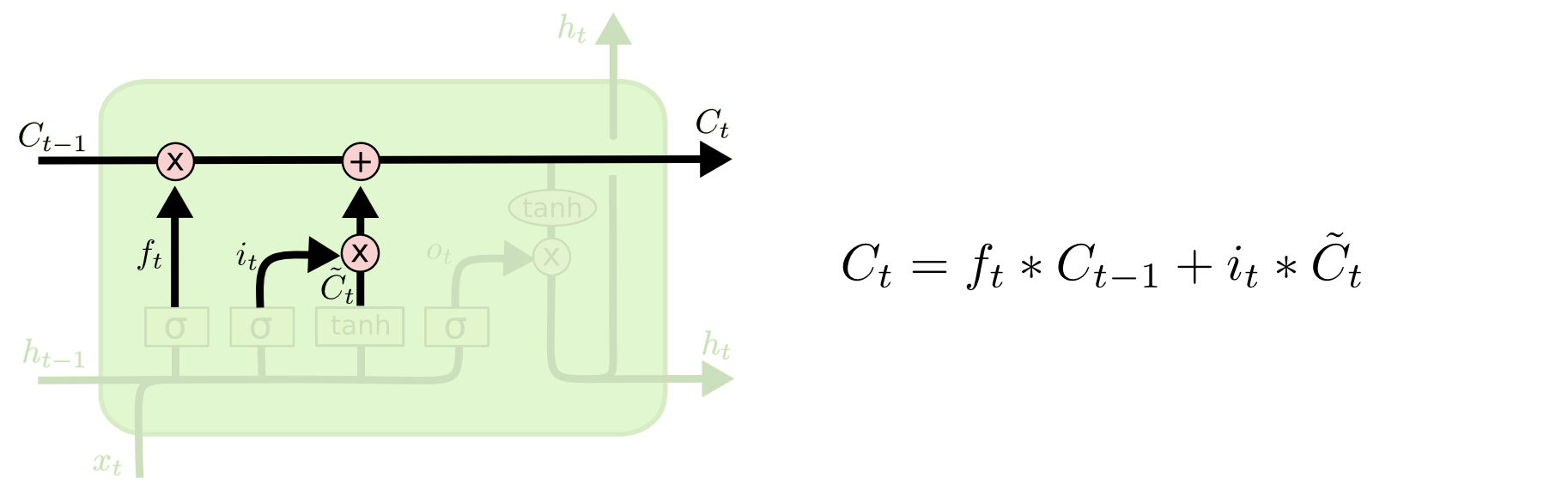
Далее необходимо обновить состояние прошлое ячейки \(C_{t-1}\) до нового состояния \(C_t\), определенного на прошлом шаге.
Для реализации этого умножаем прошлое состояние на \(f_{t}\) для «забывания» данных признанных ненужными на прошлом шаге. Затем добавляется \(i_t * \tilde C_t\). Это новые значения значений, выбранные ранее для запоминания.
В случае с лингвистической моделью мы забываем информацию о старом субъекте и запоминаем новую информацию, определенную на прошлом шаге.
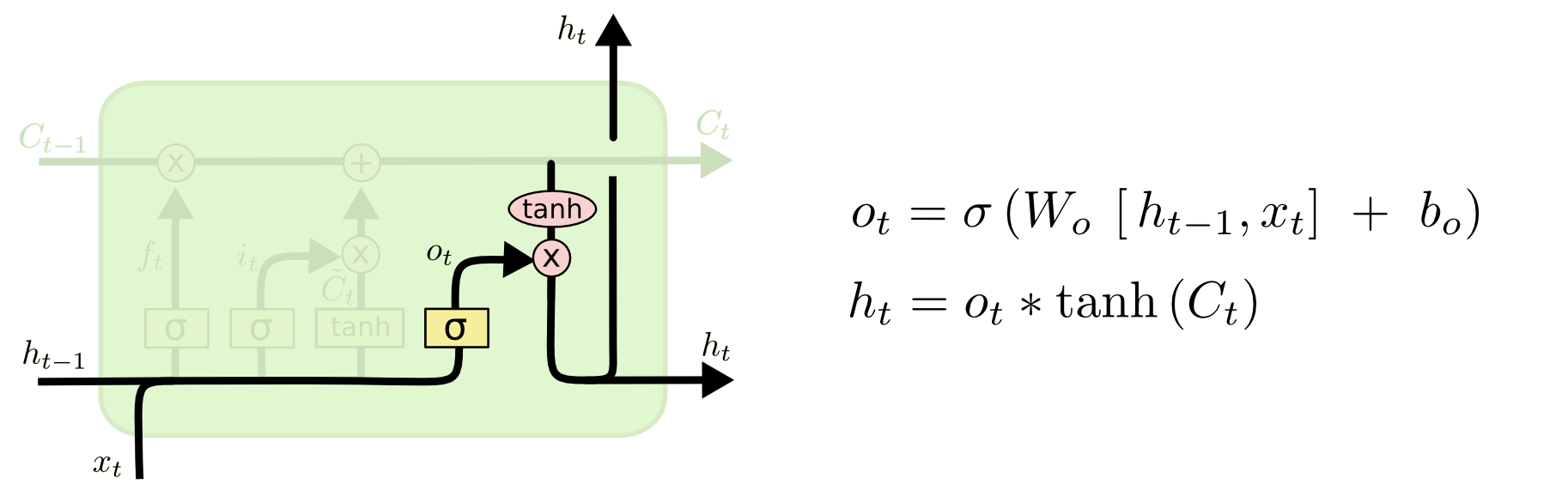
Наконец, мы должны решить, что будет на выходе ячейки. Этот выход формируется на базе состояния ячейки, но является его фильтрованной версией. Сначала запускается сигмоидный слой, определяющий какая часть состояния ячейки будет передана на выход. После чего состояние ячейки подается на функцию tanh (выходные значения между -1 и 1) и умножается на выход сигмовидного вентиля, определяющего частичность выхода состояния.
В примере с лингвистической моделью, это может быть предмет, увиденный сетью и требующийся для вывода информации, имеющей отношение к глаголу. Например, определение множественного или единственного числа субъекта для определения формы глагола следующего далее.
Вариации LSTM-сетей
Выше мы рассмотрели классические LSTM-сети, однако существует множество их вариаций. На самом деле, фактически в каждом исследовании, с использованием LSTM-сетей используется не совсем классическая модель. Различия, как правило, незначительны, но стоит отметить основные.
Один из популярных варианты LSTM-сетей, введенный Gers & Schmidhuber (2000) добавляет «Глазки», что определяет возможность вентилям наблюдать за состоянием ячейки.
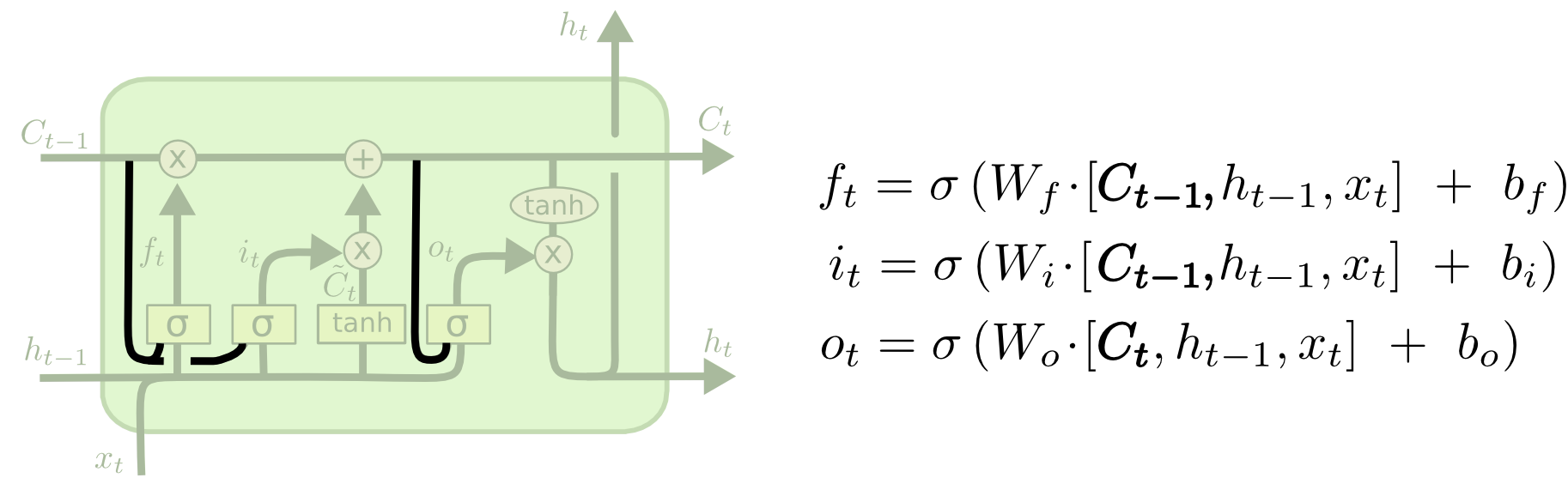
На диаграмме выше «глазки» добавлены для всех вентилей, однако во многих статьях «глазки» используются не для всех, а только для некоторых вентилей.
Другим вариантом является комбинирование вентилей «забывания» и входных вентилей. Тогда вместо того, чтобы по отдельность решать какую информацию забывать, а какую запоминать эти операции производятся совместно, и тогда забывание информации производится только с замещением.
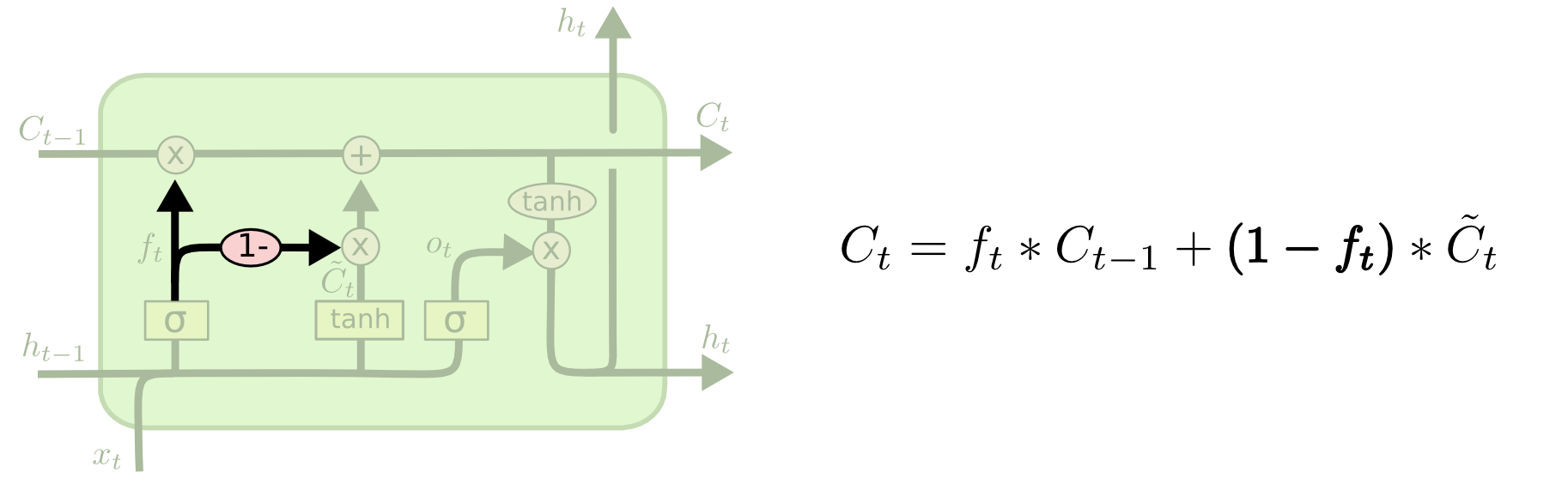
Чуть более серьезное изменение LSTM-сетей — Рекуррентный модуль с затворами (Gated Recurrent Unit) или GRU, введенные Cho, и др. (2014). Этот подход комбинирует вентили «забывания» и входные вентили в единый вентиль обновления. Кроме того объединяется состояние и скрытое состояние ячейки и содержит некоторые другие менее значительные изменения. Полученная модель является более простой, чем классическая LSTM модель и становится все более популярной.

Это лишь некоторые вариации LSTM-модели. Существует множество других, таких как глубокие вентильные рекуррентные нейронные сети (Depth Gated RNNs) Yao и др. (2015). Кроме того предлагаются принципиально иные подходы, такие как часовые нейронные сети (Clockwork RNNs) предложенные Koutnik и др. (2014).
Какой из этих вариантов лучше? Имеются ли различия? Greff и др (2015) делая неплохое сравнение популярных вариантов, приходят к выводу о том, что они примерно одинаковы. Jozefowicz, и др. (2015) протестировав более 10 тысяч архитектур рекуррентных нейронных сетей, говорят о том, что некоторые из них работали лучше чем LSTM в специализированных задачах.
Заключение
Ранее говорилось о том, что достигнуты выдающиеся результаты с рекуррентными нейронными сетям. Значительная часть с использованием LSTM-сетей. Эти сети, действительно, работают лучше других известных во многих задачах.
Будучи записанными как набор уравнений LSTM-сети выглядят весьма пугающе, будем надеяться, что после прочтения статьи читатель стал лучше понимать особенности этой архитектуры.
LSTM-сети были большим прогрессом в рекуррентных нейронный сетях. И естественно задаваться вопросом о том, каким будет следующих скачек в исследовании рекуррентных нейронных сетей.
Оригинал: Understanding LSTM Networks