
Оригинал инструкции был составлен Джастином Джонсоном.
Мы будем использовать язык программирования Python для всех заданий этого курса. Python это отличный универсальный язык программирования сам по себе, но с помощью некоторых популярных библиотек (numpy, scipy, matplotlib) он становиться мощным окружением для научных вычислений.
Несмотря на предположение, что читатель имеет некоторый опыт использования Python и numpy, для этот раздел послужит быстрым вводным курсом по языку программирования Python и использовании Python для научных вычислений для читателей с недостаточными навыками.
Некоторые из вас уже могут иметь опыт работы в Matlab, в таком случае мы рекомендуем ознакомиться со страницей numpy для пользователей Matlab.
Вы также можете найти эту инструкцию в формате IPython notebook здесь созданную Владимиром Кулешовым and Исааком Касвеллом для CS 228 и Google Сolaboratory версию созданную нами.
Python
Python это высокоуровневый, динамически типизированный мультипарадигменный язык программирования. О коде написанном на Python, часто говорят, что он выглядит почти как псевдокод, поскольку он позволяет выражать очень сложные идеи в минимальном количестве строк кода, при этом сохраняя его читабельность. Как пример ниже приведена реализация алгоритма быстрой сортировки в Python:
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
print(quicksort([3,6,8,10,1,2,1])) # Выводит "[1, 1, 2, 3, 6, 8, 10]"Версии Python
На данный момент существует две различные поддерживаемые версии Python, 2.7 и 3.x. Несколько сбивает то, что Python 3.0 представил много обратно-несовместимых изменений в языке, поэтому код написанный для 2.7 может не работать на версии >3.5 и наоборот. Для этого занятия все строки кода написаны на Python 3.6.
Вы можете проверить свою версию Python, выполнив в командной строке: python —version.
Базовые типы данных
Как и большинство языков, Python имеет ряд базовых типов, включая целые, вещественные, булевые и строковые. Эти типы данных ведут себя так же как и в других языках программирования.
Числа
Работа с целыми и вещественными числами осуществляется так же, как и в других языках программирования:
x = 3
print(type(x)) # Выводит "<class 'int'>"
print(x) # Выводит "3"
print(x + 1) # Сложение; выводит "4"
print(x - 1) # Вычитание; выводит "2"
print(x * 2) # Умножение; выводит "6"
print(x ** 2) # Возведение в степень; выводит"9"
x += 1
print(x) # Выводит "4"
x *= 2
print(x) # Выводит "8"
y = 2.5
print(type(y)) # Выводит "<class 'float'>"
print(y, y + 1, y * 2, y ** 2) # Выводит "2.5 3.5 5.0 6.25"Заметьте, что в отличие от многих языков, Python не имеет унарных операторов инкремента (x++) и декремента(x—).
Python также имеет встроенные типы для комплексных чисел; все детали вы можете найти в документации.
Булевы (логические)
Python реализует все привычные операторы булевой логики, но использует английские слова вместо символов (&&, ||, и т.д..):
t = True
f = False
print(type(t)) # Выводит "<class 'bool'>"
print(t and f) # Логическое И; Выводит "False"
print(t or f) # Логическое ИЛИ; Выводит "True"
print(not t) # Логическое НЕ; Выводит "False"
print(t != f) # Логическое XOR; Выводит "True"Строковые
Python имеет отличную поддержку для строковых значений:
hello = 'hello' # Строковые символы могут быть заключены в одинарные кавычки
world = "world" # или двойные кавычки; это неважно
print(hello) # Выводит "hello"
print(len(hello)) # Длина строки; Выводит "5"
hw = hello + ' ' + world # Сложение строк
print(hw) # Выводит "hello world"
hw12 = '%s %s %d' % (hello, world, 12) # форматирование строки в стиле sprintf
print(hw12) # Выводит "hello world 12"
hw13 = '{} {} - {}'.format(hello, world, 13) # другой способ форматирования строки
print(hw13) # Выводит "hello world - 13"Строковые объекты имеют массу полезных методов; например:
s = "hello"
print(s.capitalize()) # Озаглавливает первую букву строки; Выводит "Hello"
print(s.upper()) # Переводит строку в верхний регистр; Выводит "HELLO"
print(s.rjust(7)) # Выравнивает строку по правому краю с заполнением с помощью пробелов; Выводит " hello"
print(s.center(7)) # Выравнивает строку по центру с заполнением с помощью пробелов; Выводит " hello "
print(s.replace('l', '(ell)')) # Заменяет все экземпляры одной подстроки другой;
# Выводит "he(ell)(ell)o"
print(' world '.strip()) # Убирает пробелы в начале и в конце строки; Выводит "world"Вы можете найти список всех строковых методов в документации.
Контейнеры
Python включает несколько встроенных типов контейнеров: списки, словари, множества и кортежи.
Списки (List)
Список в Python используется, как массив, но он способен изменять свой размер и содержать элементы разных типов:
xs = [3, 1, 2] # Создает список
print(xs, xs[2]) # Выводит "[3, 1, 2] 2"
print(xs[-1]) # Отрицательные индексы считаются от конца списка; Выводит "2"
xs[2] = 'foo' # Списки могут содержать элементы разных типов
print(xs) # Выводит "[3, 1, 'foo']"
xs.append('bar') # Добавляет новый элемент в конец списка
print(xs) # Выводит "[3, 1, 'foo', 'bar']"
x = xs.pop() # Удаляет и возвращает последний элемент списка
print(x, xs) # Выводит "bar [3, 1, 'foo']"Как обычно, вы можете найти всю дополнительную информацию о списках в документации.
Срез: В дополнение к традиционному способу доступа к элементам списка по одному за раз, Python обеспечивает краткий синтаксис для доступа к подспискам; Это называется срез:
nums = list(range(5)) # range встроенная функция которая создает список целых чисел
print(nums) # Выводит "[0, 1, 2, 3, 4]"
print(nums[2:4]) # Делает срез от индекса 2 до 4 (не включительно); Выводит "[2, 3]"
print(nums[2:]) # Делает срез от индекса 2 до конца; Выводит "[2, 3, 4]"
print(nums[:2]) # Делает срез начала до индекса 2 (не включительно); Выводит "[0, 1]"
print(nums[:]) # Делает срез всего списка; Выводит "[0, 1, 2, 3, 4]"
print(nums[:-1]) # Индексы среза могут быть отрицательными; Выводит "[0, 1, 2, 3]"
nums[2:4] = [8, 9] # Присваивание нового подсписка к срезу
print(nums) # Выводит "[0, 1, 8, 9, 4]"Как вы заметили, отрицательные индексы обозначают номер элемента с конца списка.
Мы еще встретимся со срезами в контексте массивов numpy.
Циклы: Вы можете перебирать элементы списка следующим образом:
animals = ['cat', 'dog', 'monkey']
for animal in animals:
print(animal)
# Выводит "cat", "dog", "monkey", каждое на новой строчке.Если вы хотите получить доступ к номеру индекса каждого элемента внутри цикла, используйте встроенную функцию enumerate:
animals = ['cat', 'dog', 'monkey']
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# Выводит "#1: cat", "#2: dog", "#3: monkey", каждое на новой строчкеГенератор списка (List comprehensions): Во время написания кода часто необходимо трансформировать один тип данных в другой. В качестве простого примера рассмотрим следующий код который вычисляет квадраты чисел:
nums = [0, 1, 2, 3, 4]
squares = []
for x in nums:
squares.append(x ** 2)
print(squares) # Выводит [0, 1, 4, 9, 16]Вы можете сделать этот код проще используя генератор списков:
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares) # Выводит [0, 1, 4, 9, 16]Генераторы списков также могут содержать условия:
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print(even_squares) # Выводит "[0, 4, 16]"Словари
Словарь хранит пары (ключ, значение), он схож с Map в Java или Object в Javascript. Вы можете использовать его следующим образом:
d = {'cat': 'cute', 'dog': 'furry'} # Создает новый словарь с какими-то данными
print(d['cat']) # Получает запись из словаря; Выводит "cute"
print('cat' in d) # Проверяет имеет ли словарь заданный ключ; Выводит "True"
d['fish'] = 'wet' # Заносит запись в словарь
print(d['fish']) # Выводит "wet"
# print(d['monkey']) # KeyError: 'monkey' не является ключом в d
print(d.get('monkey', 'N/A')) # Получает запись с дефолтным значением при ошибке; Выводит "N/A"
print(d.get('fish', 'N/A')) # Получает запись с дефолтным значением при ошибке; Выводит "wet"
del d['fish'] # Удаляет элемент из словаря
print(d.get('fish', 'N/A')) # "fish" больше не является ключом; Выводит "N/A"Вы можете найти всю необходимую дополнительную информацию по словарям в документации.
Циклы: С их помощью легко проходить по всем ключам в словаре:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:
legs = d[animal]
print('A %s has %d legs' % (animal, legs))
# Выводит "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"Если необходимо получить доступ к ключам и их соответствующим значениям, можно воспользоваться методом items:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal, legs in d.items():
print('A %s has %d legs' % (animal, legs))
# Выводит "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"Генератор словарей (Dictionary comprehensions): Схож с генератором списков, но позволяет вам с легкостью создавать словари. К примеру:
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print(even_num_to_square) # Выводит "{0: 0, 2: 4, 4: 16}"Множества (Set)
Множество — это неупорядоченная коллекция определенных элементов. Простой пример множества приведен в коде ниже:
animals = {'cat', 'dog'}
print('cat' in animals) # Check if an element is in a set; Выводит "True"
print('fish' in animals) # Выводит "False"
animals.add('fish') # Add an element to a set
print('fish' in animals) # Выводит "True"
print(len(animals)) # Number of elements in a set; Выводит "3"
animals.add('cat') # Adding an element that is already in the set does nothing
print(len(animals)) # Выводит "3"
animals.remove('cat') # Remove an element from a set
print(len(animals)) # Выводит "2"Всю необходимую информацию о множествах вы можете найти в документации.
Циклы: Перемещение по элементам множества имеет такой же синтаксис как и в случае со списком. Однако, поскольку множество не упорядочено, невозможно сделать предположение о порядке посещения его отдельных элементов:
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# Выводит "#1: fish", "#2: dog", "#3: cat" Генератор множеств (Set comprehensions): Подобно Спискам и словарям, множества могут быть легко созданы с помощью генератора множеств:
from math import sqrt
nums = {int(sqrt(x)) for x in range(30)}
print(nums) # Выводит "{0, 1, 2, 3, 4, 5}"Кортежи (Tuples)
Кортеж — это упорядоченный (неизменяемый) список значений. Во многом кортеж похож на контейнер типа список; Одно из важнейших отличий кортежа от списка заключается в том, что элементы первого могут быть использованы в качестве ключей в словарях, а также являться элементами множества. Ниже приведен простейший пример:
d = {(x, x + 1): x for x in range(10)} # Создает словарь, ключи которого являются кортежами
t = (5, 6) # Создает кортеж
print(type(t)) # Выводит "<class 'tuple'>"
print(d[t]) # Выводит "5"
print(d[(1, 2)]) # Выводит "1"В документации вы сможете найти более подробную информацию о кортежах.
Функции
В Python все функции определяются ключевым словом def. Пример:
def sign(x):
if x > 0:
return 'positive'
elif x < 0:
return 'negative'
else:
return 'zero'
for x in [-1, 0, 1]:
print(sign(x))
# Выводит "negative", "zero", "positive"Часто функции определяются с необязательными входными параметрами, как в примере ниже:
def hello(name, loud=False):
if loud:
print('HELLO, %s!' % name.upper())
else:
print('Hello, %s' % name)
hello('Bob') # Выводит "Hello, Bob"
hello('Fred', loud=True) # Выводит "HELLO, FRED!"Более подробную информацию о функциях в Python вы можете найти в документации.
Классы
Синтаксис определения класса выглядит следующим образом:
class Greeter(object):
# Конструктор
def __init__(self, name):
self.name = name # Создает экземпляр переменной
# Метод экземпляра
def greet(self, loud=False):
if loud:
print('HELLO, %s!' % self.name.upper())
else:
print('Hello, %s' % self.name)
g = Greeter('Fred') # Создает экземпляр класса Greeter
g.greet() # Вызывает метод экземпляра; Выводит "Hello, Fred"
g.greet(loud=True) # Вызывает метод экземпляра; Выводит "HELLO, FRED!"Подробнее о классах в Python вы можете узнать в документации.
Numpy
Numpy — это ключевая библиотека для научных вычислений в Python. Она реализует высокопроизводительные многомерные массивы и инструменты для работы с этими массивами. Если вы уже знакомы с MATLAB, то для начала работы с Numpy вам будет полезно ознакомиться с этим руководством.
Для использования Numpy необходимо импортировать модуль numpy. Традиционно (по соглашению) это делается следующим образом:
import numpy as npМассивы
Массивы в numpy представляют собой наборы значений одного типа, проиндексированные с помощью кортежа неотрицательных целых чисел. Количество измерений — это ранг массива; форма массива — это кортеж целых чисел задающих размер каждого измерения массива.
Инициализировать массив numpy можно с помощью вложенных списков Python, а для получения доступа к его элементам используются квадратные скобки:
import numpy as np
a = np.array([1, 2, 3]) # Создает 1 ранговый массив
print(type(a)) # Выводит "<class 'numpy.ndarray'>"
print(a.shape) # Выводит "(3,)"
print(a[0], a[1], a[2]) # Выводит "1 2 3"
a[0] = 5 # Изменяет элемент массива
print(a) # Выводит "[5, 2, 3]"
b = np.array([[1,2,3],[4,5,6]]) # Создает 2 ранговый массив
print(b.shape) # Выводит "(2, 3)"
print(b[0, 0], b[0, 1], b[1, 0]) # Выводит "1 2 4"Numpy также предоставляет множество функций для создания массивов:
import numpy as np
a = np.zeros((2,2)) # Создает массив нулей
print(a) # Выводит "[[ 0. 0.]
# [ 0. 0.]]"
b = np.ones((1,2)) # Создает массив
print(b) # Выводит "[[ 1. 1.]]"
c = np.full((2,2), 7) # Создает массив с заданным значением элементов
print(c) # Выводит "[[ 7. 7.]
# [ 7. 7.]]"
d = np.eye(2) # Создает тождественную матрицу 2х2
print(d) # Выводит "[[ 1. 0.]
# [ 0. 1.]]"
e = np.random.random((2,2)) # Создает массив заполненный случайным образом
print(e) # Может выводить "[[ 0.91940167 0.08143941]
# [ 0.68744134 0.87236687]]"Больше о методах создания массивов вы можете прочитать в документации.
Индексирование массивов
Numpy предлагает несколько способов индексирования массивов.
Срез: Подобно спискам Python, для массивов numpy может быть получен срез. Поскольку массивы многомерны необходимо определять срез для каждого измерения:
import numpy as np
# Создает ниже приведенный массив ранга 2 с формой (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Использует срезку, чтобы вытащить подмассив состоящий из первых двух строк
# и колонок 1 и 2; b - это ниже приведенный массив формы (2, 2):
# [[2 3]
# [6 7]]
b = a[:2, 1:3]
# Срез массива ссылается на те же экземпляры данных, поэтому их изменение
# приведет к изменениям в оригинальном массиве.
print(a[0, 1]) # Выводит "2"
b[0, 0] = 77 # b[0, 0] это тот же кусок данных что и a[0, 1]
print(a[0, 1]) # Выводит "77"Вы также можете комбинировать индексацию с помощью срезов и целых чисел. Однако это приведет к получению массива более низкого ранга, чем исходный массив. Заметьте, что это сильно отличается от способа которым MATLAB обрабатывает срезы массивов:
import numpy as np
# Создает ниже приведенный массив ранга 2 с формой (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])Два способа доступа к данным в средней строке массива. Комбинирование целочисленной индексации со срезами дает массив более низкого ранга, при использовании исключительно срезов получается массив того же ранга что и исходный массив:
row_r1 = a[1, :] # Ранг 1 просмотр второй строки a
row_r2 = a[1:2, :] # Ранг 2 просмотр второй строки a
print(row_r1, row_r1.shape) # Выводит "[5 6 7 8] (4,)"
print(row_r2, row_r2.shape) # Выводит "[[5 6 7 8]] (1, 4)"
# То же самое получается при доступе к столбцам массива:
col_r1 = a[:, 1]
col_r2 = a[:, 1:2]
print(col_r1, col_r1.shape) # Выводит "[ 2 6 10] (3,)"
print(col_r2, col_r2.shape) # Выводит "[[ 2]
# [ 6]
# [10]] (3, 1)"Целочисленная индексация массивов: При использовании срезки для доступа к элементам numpy массива, результирующий массив всегда будет являться подмассивом исходного массива. Использование целочисленной индексации же, напротив, позволяет создавать произвольные массивы используя данные из другого массива. Пример приведен ниже:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
# Пример целочисленной индексации массива.
# Возвращаемый массив имеет форму (3,) и
print(a[[0, 1, 2], [0, 1, 0]]) # Выводит "[1 4 5]"
# Пример целочисленной индексации приведенный выше эквивалентен следующему:
print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # Выводит "[1 4 5]"
# При использовании целочисленной индексации вы можете несколько раз использовать
# один и тот же элемент из исходного массива:
print(a[[0, 0], [1, 1]]) # Выводит "[2 2]"
# Эквивалент к примеру приведенному выше
print(np.array([a[0, 1], a[0, 1]])) # Выводит "[2 2]"Одним из полезных трюков с индексацией целочисленных массивов является выбор или изменение одного элемента из каждой строки матрицы:
import numpy as np
# Создает новый массив из которого мы будем выбирать элементы
a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
print(a) # Выводит "array([[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9],
# [10, 11, 12]])"
# Создает массив индексов
b = np.array([0, 2, 0, 1])
# Выбирает один элемент из каждой строки используя индексы в b
print(a[np.arange(4), b]) # Выводит "[ 1 6 7 11]"
# Изменяет один элемент из каждой строки используя индексы в b
a[np.arange(4), b] += 10
print(a) # Выводит "array([[11, 2, 3],
# [ 4, 5, 16],
# [17, 8, 9],
# [10, 21, 12]])Булевая индексация массивов: Логическое индексирование массива позволяет выбирать произвольные элементы массива. Часто этот тип индексирования используется для выбора элементов массива, удовлетворяющих некоторому условию. Ниже приведен пример:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
bool_idx = (a > 2) # Находит элементы а , которые > 2;
# возвращает numpy массив булевых значений той же
# формы как и а, где каждая ячейка bool_idx говорит о том
# удовлетворяет ли данный элемент из a условию: элемент > 2.
print(bool_idx) # Выводит "[[False False]
# [ True True]
# [ True True]]"
# Используя булеву индексацию мы создаем массив 1 ранга
# состоящего из элементов, соответствующих истинным значениям
# из bool_idx
print(a[bool_idx]) # Выводит "[3 4 5 6]"
# Все вышесказанное мы можем сделать с помощью одной строчки:
print(a[a > 2]) # Выводит "[3 4 5 6]"Для краткости опущено много деталей об индексации массива numpy; если вы хотите узнать больше, то советуем прочесть эту документацию.
Типы данных
Каждый numpy массив это набор элементов одного типа. Numpy предоставляет большое множество числовых типов данных которые можно использовать для создания массивов. Numpy пытается предположить какой тип данных вы хотите использовать при создании массива, но функции которые строят массивы обычно имеют опциональный аргумент, чтобы явно указать тип данных. Ниже приведен пример:
import numpy as np
x = np.array([1, 2]) # Позволяет numpy выбрать тип данных
print(x.dtype) # Выводит "int64"
x = np.array([1.0, 2.0]) # Позволяет numpy выбрать тип данных
print(x.dtype) # Выводит "float64"
x = np.array([1, 2], dtype=np.int64) # Вынуждает применить нужный тип данных
print(x.dtype) # Выводит "int64"Всю дополнительную информацию о типах данных вы можете найти в документации.
Математика массивов
Базовые математические функции работают с массивами поэлементно, и доступны для вызова двумя способами: использованием перегруженных операторов, использованием функций из модуля numpy:
import numpy as np
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# Поэлементное сложение; оба производят массив
# [[ 6.0 8.0]
# [10.0 12.0]]
print(x + y)
print(np.add(x, y))
# Поэлементное вычитание; оба производят массив
# [[-4.0 -4.0]
# [-4.0 -4.0]]
print(x - y)
print(np.subtract(x, y))
# Поэлементное умножение; оба производят массив
# [[ 5.0 12.0]
# [21.0 32.0]]
print(x * y)
print(np.multiply(x, y))
# Поэлементное деление; оба производят массив
# [[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]]
print(x / y)
print(np.divide(x, y))
# Поэлементное взятие квадратного корня; оба производят массив
# [[ 1. 1.41421356]
# [ 1.73205081 2. ]]
print(np.sqrt(x))Заметьте, что в отличие от MATLAB, * — это поэлементное умножение, а не матричное. Для вычисления внутренних произведений векторов, умножения матриц и умножения векторов на матрицы, используется функция dot, доступная как в качестве модуля numpy, так и в качестве встроенного метода объектов типа массив:
import numpy as np
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])
v = np.array([9,10])
w = np.array([11, 12])
# Внутреннее произведение векторов; оба дают 219
print(v.dot(w))
print(np.dot(v, w))
# Матричное / векторное умножение; оба дают массив 1 ранга [29 67]
print(x.dot(v))
print(np.dot(x, v))
# Матричное / векторное умножение; оба дают массив 2 ранга
# [[19 22]
# [43 50]]
print(x.dot(y))
print(np.dot(x, y))Numpy предоставляет множество полезных функций для выполнения вычислений над массивами; одна из самых полезных это функция sum:
import numpy as np
x = np.array([[1,2],[3,4]])
print(np.sum(x)) # Вычисляет сумму всех элементов; Выводит "10"
print(np.sum(x, axis=0)) # Вычисляет сумму каждого столбца; Выводит "[4 6]"
print(np.sum(x, axis=1)) # Вычисляет сумму каждой строки; Выводит "[3 7]"Полный список математических функций, предоставляемых numpy, вы можете найти в документации.
Кроме вычисления математических функций над массивами, часто необходимо изменять или иначе манипулировать данными в массивах. Простейший пример операции такого типа это транспонирование матрицы; Чтобы транспонировать матрицу, достаточно использовать атрибут T:
x = np.array([[1,2], [3,4]])
print(x) # Выводит "[[1 2]
# [3 4]]"
print(x.T) # Выводит "[[1 3]
# [2 4]]"Заметьте что попытка транспонировать массив 1 ранга ни к чему не приводит:
v = np.array([1,2,3])
print(v) # Выводит "[1 2 3]"
print(v.T) # Выводит "[1 2 3]"Numpy поддерживает гораздо больше функций для манипуляций с массивами; полный список вы можете посмотреть в документации.
Транслирование (Broadcasting)
Транслирование (Broadcasting) — это мощный механизм, который позволяет numpy работать с массивами различных форм при выполнении арифметических операций. Часто имеется один малый и один большой массивы, и возникает необходимость использовать малый массив несколько раз, чтобы выполнить некоторые операции над большим массивом.
Для примера предположим, что нам необходимо добавить константный вектор в каждую строку матрицы. Это можно сделать следующим образом:
import numpy as np
# Мы будем добавлять вектор v в каждую строку матрицы x,
# сохраняя результат в матрице y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = np.empty_like(x) # Создает пустую матрицу, с формой матрицы x
# Добавим вектор v в каждую строку матрицы x с явным циклом
for i in range(4):
y[i, :] = x[i, :] + v
# теперь у содержит следующее:
# [[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]
print(y)Это работает; однако когда матрица x очень большая, вычисления в явном цикле в Python может быть медленным. Заметьте, что добавление вектора v к каждой строке матрицы x, эквивалентно формированию матрицы vv путем укладки нескольких копий v вертикально, затем выполняется поэлементное сложение x и vv. Мы можем применить данный подход следующим образом:
import numpy as np
# Мы будем добавлять вектор v в каждую строку матрицы x,
# сохраняя результат в матрице y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
vv = np.tile(v, (4, 1)) # Укладывает 4 копии вектора v друг на друга
print(vv) # Выводит "[[1 0 1]
# [1 0 1]
# [1 0 1]
# [1 0 1]]"
y = x + vv # Складывает x и vv поэлементно
print(y) # Выводит "[[ 2 2 4
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"Транслирование numpy позволяет выполнять такие вычисления без создания дополнительных копий v. Рассмотрим версию, использующую broadcasting:
# Мы будем добавлять вектор v в каждую строку матрицы x,
# сохраняя результат в матрице y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = x + v # Суммирует v с каждой строкой x используя транслирование
print(y) # Выводит "[[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"Строка y = x + v работает несмотря на то, что x имеет форму (4, 3), а v имеет форму (3,) благодаря транслированию. Причем работает так, как если бы v имел форму (4, 3), где каждая строка была бы копией v, а суммирование выполнялось поэлементно.
Транслирование двух массивов следует следующим правилам:
- Если массивы не имеют одинаковый ранг, дополняет форму массива низшего ранга единицами, пока обе формы не будут иметь одинаковую длину.
- Два массива считаются совместными в одном измерении, если они имеют одинаковый размер в этом измерении или если один из массивов имеет размер равный 1 в этом измерении.
- Массивы могут транслироваться вместе, если они совместны во всех измерениях.
- После транслирования каждый массив ведет себя так, как если бы он имел форму равную элементному максимуму форм двух входных массивов.
- В любом измерении, где один массив имеет размер равный 1, и другой имеет размер больший чем 1, первый массив ведет себя так, как если бы был скопирован на все измерение.
Если все вышесказанное вызывает у вас вопросы, попробуйте обратиться к объяснению из документации или этого объяснения.
Функции, которые поддерживают транслирование называют универсальными функциями. Список всех универсальных функций вы можете найти в документации.
Вот немного примеров применения транслирования:
import numpy as np
# Вычисляет внешнее произведение векторов
v = np.array([1,2,3]) # v имеет форму (3,)
w = np.array([4,5]) # w имеет форму (2,)
# Чтобы вычислить внешнее произведение, мы сначала переформируем v в столбец
# вектор формы (3, 1); после этого мы можем транслировать его с w для получения результата
# выходная форма (3, 2), получилась после внешнего произведения векторов v и w:
# [[ 4 5]
# [ 8 10]
# [12 15]]
print(np.reshape(v, (3, 1)) * w)
# Добавляет вектор к каждой строке матрицы
x = np.array([[1,2,3], [4,5,6]])
# x имеет форму (2, 3) и v имеет форму (3,) так что они транслируются в форму (2, 3),
# давая следующую матрицу:
# [[2 4 6]
# [5 7 9]]
print(x + v)
# Добавляет вектор в каждый столбец матрицы
# x имеет форму (2, 3) и w имеет форму (2,).
# Если мы транспонируем x то он будет иметь форму (3, 2) и сможет быть транслирован
# с w для получения результата формы (3, 2); транспонирование этого результата
# приводит к окончательному результату формы (2, 3) в которой к каждому столбцу матрицы x
# добавлен вектор w. Конечная матрица выглядит следующим образом:
# [[ 5 6 7]
# [ 9 10 11]]
print((x.T + w).T)
# Другое решение это переформировать w в столбец, вектор формой (2, 1);
# после этого мы можем транслировать его с x чтобы вычислить тот же
# результат.
print(x + np.reshape(w, (2, 1)))
# Умножение матрицы на константу:
# x имеет форму (2, 3). Numpy обрабатывает скалярные типы, как массивы формы ();
# которые могут быть транслированы вместе в форму (2, 3), формируя
# следующий массив:
# [[ 2 4 6]
# [ 8 10 12]]
print(x * 2)Транслирование, обычно, делает код более кратким и быстрым, поэтому вы должны стараться использовать этот механизм в местах где это возможно.
Документация numpy
Этот краткий обзор охватывает много важных вещей, которые необходимо знать о numpy, но он далеко не полный. Просмотрите справочник numpy, чтобы узнать гораздо больше о данной библиотеке.
SciPy
Numpy предоставляет высокопроизводительные многоразмерные массивы и базовые инструменты для вычислений и манипуляций с ними. SciPy основан на этом, и предоставляет большой набор функций которые работают с массивами numpy и полезны для различного рода научных и инженерных приложений.
Лучший способ познакомиться с SciPy это просмотреть в документации.
Файлы MATLAB
Функции scipy.io.loadmat и scipy.io.savemat позволяют читать и записывать MATLAB файлы. Вы можете прочитать о них в документации.
Расстояние между точками
SciPy определяет некоторые полезные функции для вычисления расстояний между наборами точек.
Функция scipy.spatial.distance.pdist вычисляет расстояние между всеми парами точек в заданном наборе:
import numpy as np
from scipy.spatial.distance import pdist, squareform
# Создает следующий массив, где каждая строка - это точка в двумерном пространстве:
# [[0 1]
# [1 0]
# [2 0]]
x = np.array([[0, 1], [1, 0], [2, 0]])
print(x)
# Вычисляет Евклидово расстояние между всеми строками в x.
# d[i, j] - это Евклидово расстояние между x[i, :] и x[j, :],
# и d - это следующий массив:
# [[ 0. 1.41421356 2.23606798]
# [ 1.41421356 0. 1. ]
# [ 2.23606798 1. 0. ]]
d = squareform(pdist(x, 'euclidean'))
print(d)Вы можете прочитать об этой функции более детально в документации.
Похожая функция (scipy.spatial.distance.cdist) вычисляет расстояние между всеми парами в двух наборах точек; Вы можете прочитать о ней в документации.
Matplotlib
Matplotlib — это библиотека построения графиков. В этом разделе дано краткое введение в модуль matplotlib.pyplot, который обеспечивает систему для построения графиков схожую той, что предоставляет MATLAB.
Построение графика
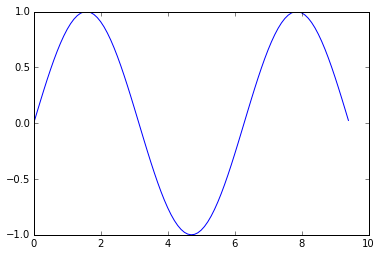
Важнейшая функция в matplotlib это — plot, которая позволяет создавать двумерные графики данных. Ниже приведен простой пример:
import numpy as np
import matplotlib.pyplot as plt
# Вычисляет координаты x и y для точек на синусоидальной кривой
x = np.arange(0, 3 * np.pi, 0.1)
y = np.sin(x)
# Строит точки на графике используя matplotlib
plt.plot(x, y)
plt.show() # Вы должны вызвать plt.show(), чтобы график появился.Выполнение кода выше, приводит к формированию следующего графика:
После небольшой доработки, мы легко сможем строить сразу несколько линий на одном графике, а также добавить заголовок, легенду, и названия осей:
import numpy as np
import matplotlib.pyplot as plt
# Вычисляет координаты x и y для точек на синусоидальной и косинусоидальной кривых
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# Строит точки на графике используя matplotlib
plt.plot(x, y_sin)
plt.plot(x, y_cos)
plt.xlabel('x axis label')
plt.ylabel('y axis label')
plt.title('Sine and Cosine')
plt.legend(['Sine', 'Cosine'])
plt.show()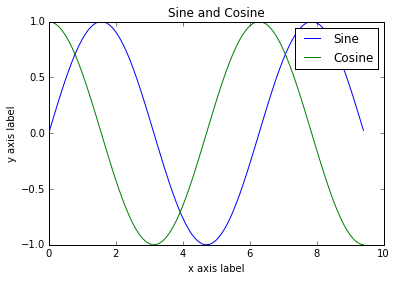
Больше информации о функции plot вы сможете найти в документации.
Построение подграфиков (subplots)
С помощью функции subplot можно построить несколько графиков на одном. Ниже приведен пример:
import numpy as np
import matplotlib.pyplot as plt
# Вычисляет координаты x и y для точек на синусоидальной и косинусоидальной кривых
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# Настройка сетки подграфиков с высотой 2 и шириной 1,
# и установка первого подграфика в активное состояние.
plt.subplot(2, 1, 1)
# Построение первого графика
plt.plot(x, y_sin)
plt.title('Sine')
# установка второго подграфика в активное состояние, и построение второго графика.
plt.subplot(2, 1, 2)
plt.plot(x, y_cos)
plt.title('Cosine')
# Показать фигуру.
plt.show()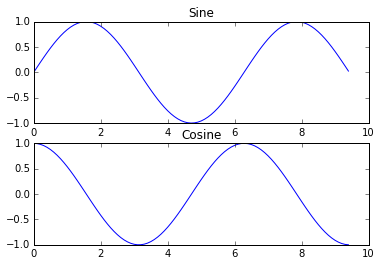
Вы можете прочитать больше о функции subplot в документации.
Изображения
Чтобы показать изображения можно использовать функцию imshow. Ниже приведен пример:
import numpy as np
import matplotlib.pyplot as plt
img = plt.imread('cat.jpg')
img_tinted = img * [1, 0.95, 0.9]
# Показать оригинальное изображение
plt.subplot(1, 2, 1)
plt.imshow(img)
# Показать подкрашенное изображение
plt.subplot(1, 2, 2)
# Небольшая проблема imshow заключается в том, что она может дать странные результаты
# если данные представлены не в формате uint8. Чтобы обойти эту проблему, мы
# явно привели изображение к формату uint8 перед его отображением.
plt.imshow(np.uint8(img_tinted))
plt.show()
Уведомление: [0.1] Введение и установка | Digiratory